网堵新闻网5月31日电 近日,根据国际机器学习大会(International Conference on Machine Learning,简称ICML)官网消息,十大老牌网堵网址交叉信息研究院多个课题组及本科生共有23篇文章被接收,在本次会议获得丰硕成果。
国际机器学习大会是由国际机器学习学会(IMLS)主办的机器学习国际顶级会议。今年举办的第39届ICML2022共收到有效投稿论文5630篇,共计1235篇被录用,录用率为21.9%。以下为交叉信息研究院部分入选成果展示(排序不分先后)。
模态竞争:是什么让多模态联合训练在深度学习中失败了?
尽管深度多模态学习在实践中取得了显著成功,但在理论上并没有得到很好的解释。近来人们在多模态训练中观察到: 表现最好的单模态网络优于联合训练的多模态网络。这一现象是违反直觉的, 因为多个信号输入通常会带来更多的信息。该研究旨在为流行的多模态联合训练框架在神经网络中出现这种性能差距提供理论解释。
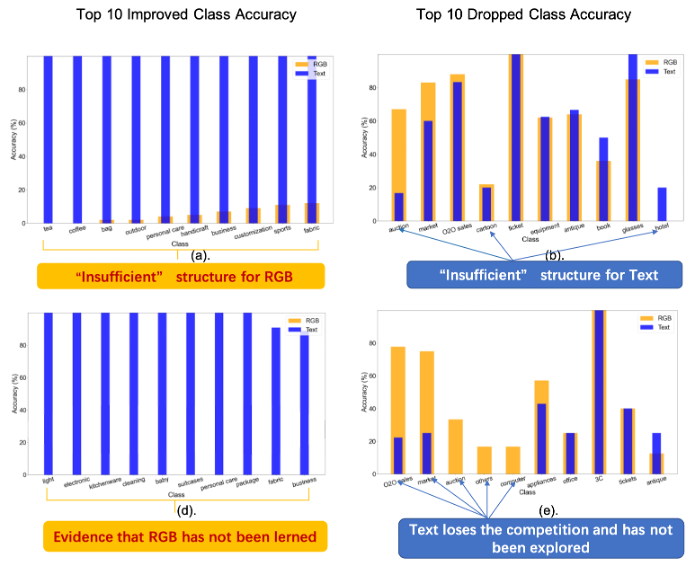
在商品分类(包含图像和文本)任务上验证模态竞争现象的存在
基于能体现多模态数据真实属性的简化数据分布,该研究证明对于通过梯度下降联合训练并由ReLU函数激活的多模态后期融合网络, 不同的模态在训练过程中将相互竞争, 导致编码网络讲只能学习到多模态的一个模态子集,该研究将这一现象刻画为模态竞争。而在竞争中失败的模态,将不会被编码网络发掘,这正是联合训练次优性的根源。通过实验,该研究说明模态竞争与多模态训练的本质行为相匹配。
论文作者:交叉信息院2020级硕士生黄钰、交叉信息院副教授黄隆波。
论文链接:https://arxiv.org/pdf/2111.11188.pdf
分析与缓解自动架构搜索中的干扰问题
权重共享,通过重复利用之前训练过的子模型的权重以减少神经结构搜索的训练成本,是一种在自动架构搜索中广泛应用的方法。然而,在实际应用中大家发现,这些子模型的估计准确率和真实准确率之间的排序相关性较低。本质上,这是由于不同子模型之间的干扰造成的。该研究通过抽取不同的子模型计算共享算子上的梯度相似度来定量的研究干扰问题。
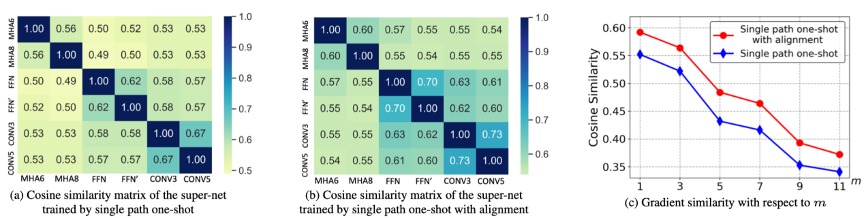
不同策略下的梯度的余弦相似度的比较
通过BERT搜索空间上的实验验证,该研究提出的两种方法都能减轻干扰并提高排序的准确率,并且两者结合可以达到更好的效果。在GLUE任务上,该研究自动搜索出来的架构显著超过了RoberTa和ELECTRA的Base模型。在BERT压缩任务,阅读理解SQuAD任务和大规模图像分类任务ImageNet上的进一步实验也证明了该研究所提出的方法的有效性和通用性。
论文作者:交叉信息院2018级博士生徐进、交叉信息院副教授李建。
论文链接:https://arxiv.org/abs/2203.12221
自组织的多项式时间协作图
协作图算法是多智能体强化学习中的一类经典方法,其通过将多智能体的联合值函数分解为一系列局部值函数的加和,显示地表达了智能体间的交互关系。在此前算法使用的协作图上,求解智能体的联合动作决策及其近似解均为NP-hard问题,这限制了已有协作图算法的性能。该研究提出了一种新的基于动态协作图的算法,以此在实现准确联合动作决策的同时维持充分的值函数表达能力。
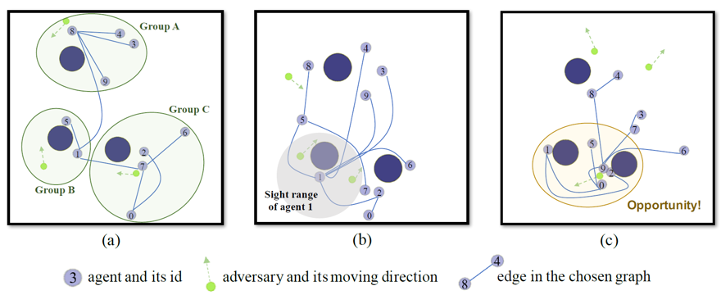
图1. 算法在“猎人-猎物”环境中学到的动态协作图
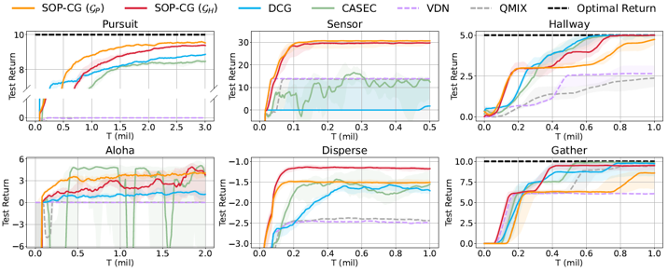
图2. 算法在多智能体合作测试集的实验结果
该研究首先构造了特殊的协作图类,这些协作图上的联合动作决策可以在多项式时间内精确求解。之后,该研究在时序差分学习的框架下设计了动态协作图的机制,算法可以根据多智能体系统状态的不同从协作图类中选择最优的协作图,这弥补了单一协作图表达能力可能不足的问题。在多个复杂的多智能体合作任务上的实验结果表明,该算法能在动态环境中自适应地选择合适的协作图结构,并取得了协作图算法中最领先的性能。
论文作者:交叉信息院2018级本科生杨乾澜,交叉信息院2018级本科生董炜隽,交叉信息院2020届姚班校友任之洲,交叉信息院2019届姚班校友、2019级交叉信息院博士研究生王鉴浩,交叉信息院2021届硕士研究生校友王同翰,交叉信息院助理教授张崇洁。
论文链接:https://arxiv.org/abs/2112.03547
阶段化的自我归纳学习:一种高效的稀疏奖赏强化学习方法
近年来,深度强化学习在许多任务中都取得了惊人的突破,但由于其对超参数极为敏感,距离实际落地还有很大差距。相比之下,监督学习是一种更加稳定的学习范式,许多基础“大模型”正是监督学习的产物。该研究提出了一种结合两种范式的框架“PAIR”,通过自我归纳产生模仿学习数据,从而将监督学习引入强化学习,高效稳定地解决极具挑战性的稀疏奖赏强化学习问题。
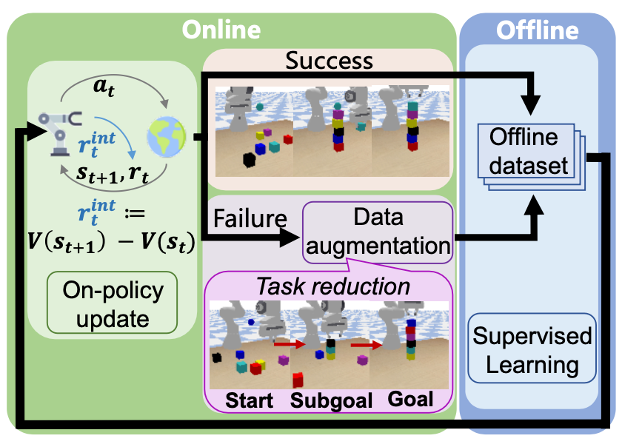
图1. PAIR算法框架总览

图2. PAIR控制机械臂堆积木塔的策略轨迹
该框架核心设计是交替进行在线和离线学习阶段:在线阶段智能体一边进行强化学习,一边收集用于离线学习的数据;离线阶段智能体在自己采集的数据中成功的轨迹上进行自我模仿学习。在线阶段还加入了自我归纳技术,让智能体把原本不会的困难任务分解成可以解决的简单的任务,大大扩充可用于离线学习的数据集。研究还引入了基于值函数的内在奖赏来提升稀疏奖赏下的学习效率。PAIR是目前已知的第一种在仅给代表成功与否的二值化奖励情况下,学会控制机械臂堆出六层高的积木塔的方法。
论文作者:交叉信息院2020级博士生李云飞、交叉信息院2019级本科生高天、交叉信息院2021届姚班校友杨家齐、交叉信息院拟入职助理教授许华哲、交叉信息院助理教授吴翼。
论文链接:https://irisli17.github.io/publication/icml22_pair/
以毒攻毒:引导深度神经网络避免优化捷径
在监督学习的分类问题与序列决策问题中,基于深度学习的算法凭借优异的性能得到了广泛的关注与应用。然而,研究人员发现深度学习网络常常倾向于寻找“捷径”的解决方案,当数据分布与训练集有稍许偏差时,这样的捷径解常常会出现灾难性的错误。该研究发现,当人们可以根据输入信号中的关键成分提供一个额外的“引导”特征时,深度神经网络可以成功避免捷径,这个“引导”特征可以是一个对于输出目标的粗略估计。这样的“引导”是根据输入信号中与任务相关成分的领域知识而获得的,在实际应用中这样的领域知识非常容易定义与获取。比如,人们能够很清楚地意识到:在视觉模仿学习中,一段视频输入的当前帧是比其他的历史帧更为重要的;在图像分类中,图片的前景物体要比背景的像素对分类任务更加关键。
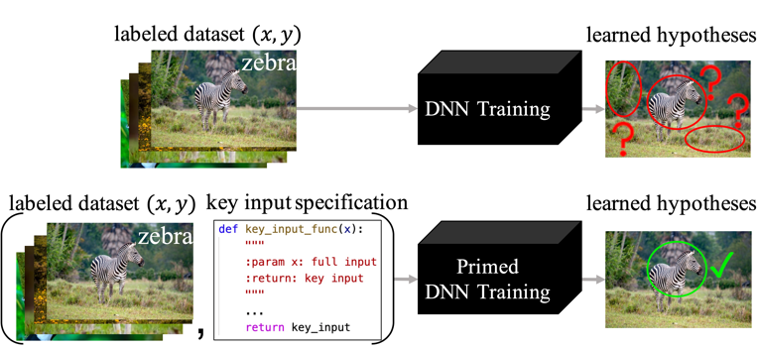
传统深度神经网络(上图)与PrimeNet(下图)的对比示意图
该研究根据这样的原理提出了“引导网络”(PrimeNet),在图像分类、机器人控制和自动驾驶任务中显著超过了现有的最优方法。并且,研究组在深度神经网络的优化角度为引导网络提供了理论保证,证明了引导特征通过为神经网络提供了一个正确的并且更简单的捷径来避免了错误的捷径方案。
论文作者:交叉信息院2020级博士生汶川、交叉信息院2020级博士生滕佳烨、交叉信息研究院助理教授高阳。
论文链接:https://alvinwen428.github.io/pdf/Fight_Fire_with_Fire__ICML2022_.pdf
基于流的部分可观测马尔科夫过程序贯信仰状态学习
部分可观测马尔科夫决策过程是对真实世界序贯决策过程的通用模型,然而其目前在高维连续空间、模型未知的条件下并未得到良好解决。其中最主要的挑战之一在于如何准确获取其信仰状态。
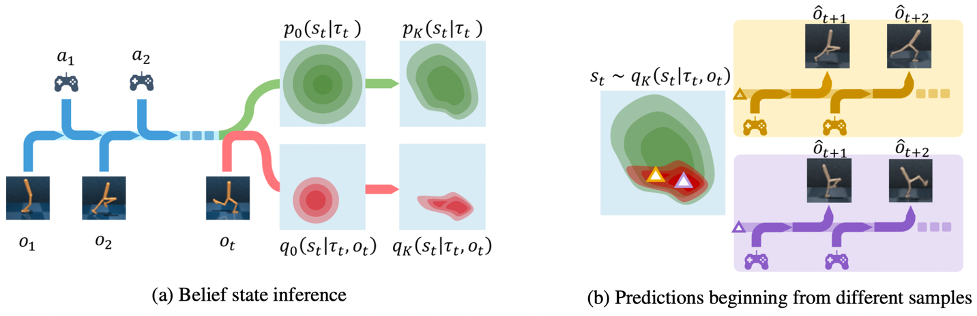
信仰状态推断(左图)与状态采样预测(右图)
该论文通过将标准化流模型整合到变分推断框架中,提出了一种通用的循环信仰状态模型,使其能够建模更加复杂的概率分布,从而能够提高重建和预测的精度,以及下游强化学习任务的性能。该方法对研发基于高维传感器输入的高级别自动驾驶与机器人等决策系统具有重要意义。
论文作者:交叉信息院2021级博士生陈晓宇、交叉信息院助理教授陈建宇。
论文链接:https://arxiv.org/abs/2205.11051
寻找量化深度神经网络中的任务最优低比特子分布
量化神经网络通常需要更小的内存占用和更低的计算复杂度,这对于高效的移动端部署至关重要。然而,神经网络量化不可避免地会导致与原始网络的分布差异,这通常会降低性能。
大量工作被提出以解决这个问题,但大多数现有方法都缺乏统计性质上的考虑,并且依赖于多种复杂的人工参数配置。该研究提出了一种自适应映射量化方法来学习模型中固有的最优潜在子分布,并用高斯混合模型 (concrete GM) 进行平滑逼近。网络权重将根据GM近似的子分布进行离散的量化映射,该子分布随着任务目标优化的训练自适应更新。
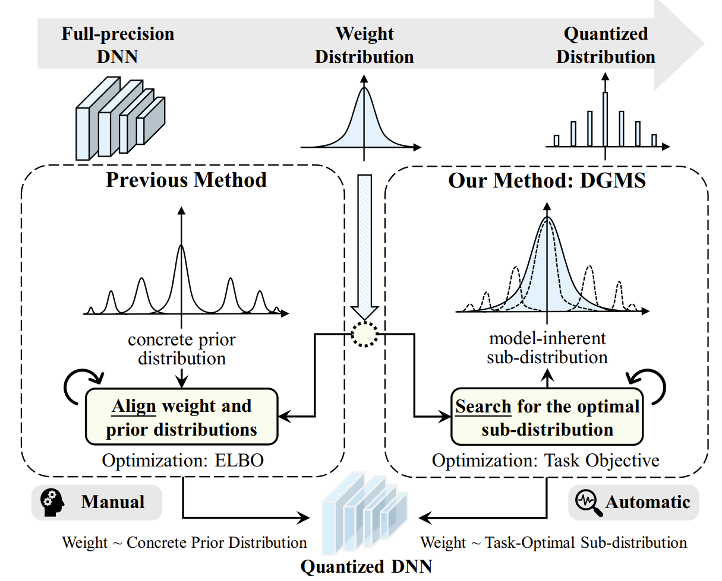
传统神经网络权重量化(左侧图)与本文提出的DGMS方法(右侧图)对比
实验证明该研究方法在各种先进网络模型上的有效性、泛化性和可迁移性。此外,该研究开发了一个移动CPU的高效部署流程Q-SIMD,在八核ARM CPU上实现了高达7.46倍的推理加速。
论文作者:交叉信息院2019级博士生谭展宏、交叉信息院2019级本科生吴梦迪、交叉信息院2019级博士生张林峰、交叉信息院助理教授马恺声。
论文链接:http://group.iiis.tsinghua.edu.cn/~maks/publications/pdf/ICML2022drp.pdf
无需预训练的高效NLP学习框架:1%算力 1%语料即可比肩预训练语言模型
预训练语言模型因其强大的性能被广泛关注。基于预训练-微调(Pretraining-Finetuning)的范式也已经成为许多NLP任务的标准方法。然而,当前通用语言模型的预训练成本极其高昂,这使得只有少数资源充足的研究机构或者组织能够对其展开探索。这种“昂贵而集权”的研究模式限制了平民研究者们为NLP社区做出贡献的边界,甚至为该领域的长期发展带来了障碍。

新提出的TLM框架与传统的预训练-微调框架的比较
该研究首次提出一种完全不需要预训练语言模型的高效学习框架:任务驱动的语言建模 (TLM, Task-driven Language Modeling)。这一框架从通用语料中筛选出与下游任务相关的子集,并将语言建模任务与下游任务进行联合训练 (如左图所示)。相较于传统的预训练模型 (例如 RoBERTa),TLM仅需要约1%的训练时间与1%的语料,即可在众多NLP任务上比肩甚至超出预训练模型的性能 (如右图所示)。作为这一领域的一项突破性进展, TLM的提出具有重要意义,它引发更多对现有预训练微调范式的思考,并进一步推动NLP民主化的进程。
论文作者:交叉信息院2018级本科生姚星丞、交叉信息院助理教授杨植麟。
论文链接:https://arxiv.org/abs/2111.04130
神经网络训练并不是在寻找驻点
非凸优化理论常常分析梯度算法寻找驻点的速率。虽然在这种分析框架下,最优的梯度算法已经被理论证明,但这些算法(如variance reduction或者Nesterov momentum)的实验性质并不明显。该研究发现这种理论偏差是由于其研究目标与实际不符造成的。研究通过大量ImageNet与Wiki102实验发现,绝大多数模型虽然损失函数收敛,而其参数并不在驻点上。
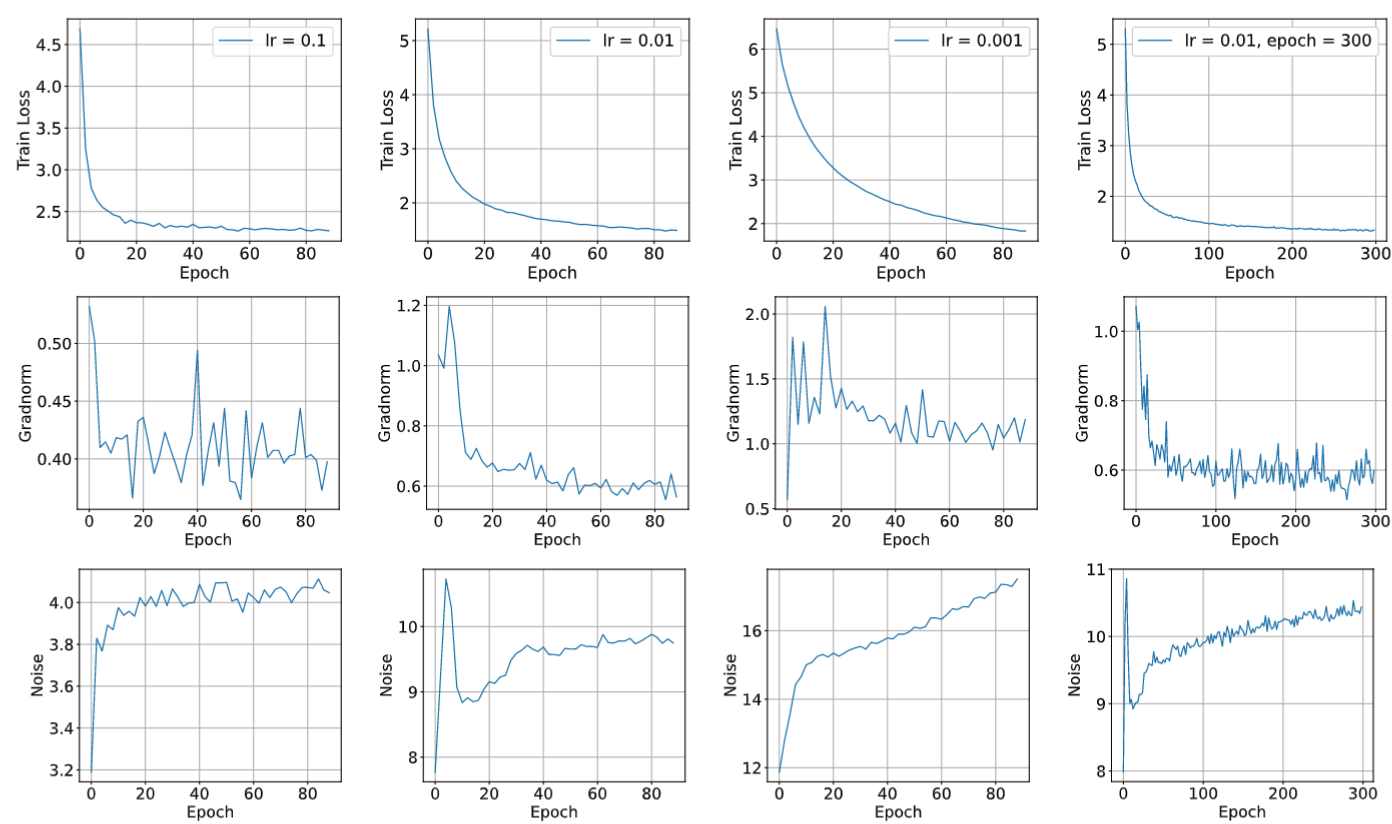
图1. 不同训练计划下的ResNet ImageNet 实验statistics
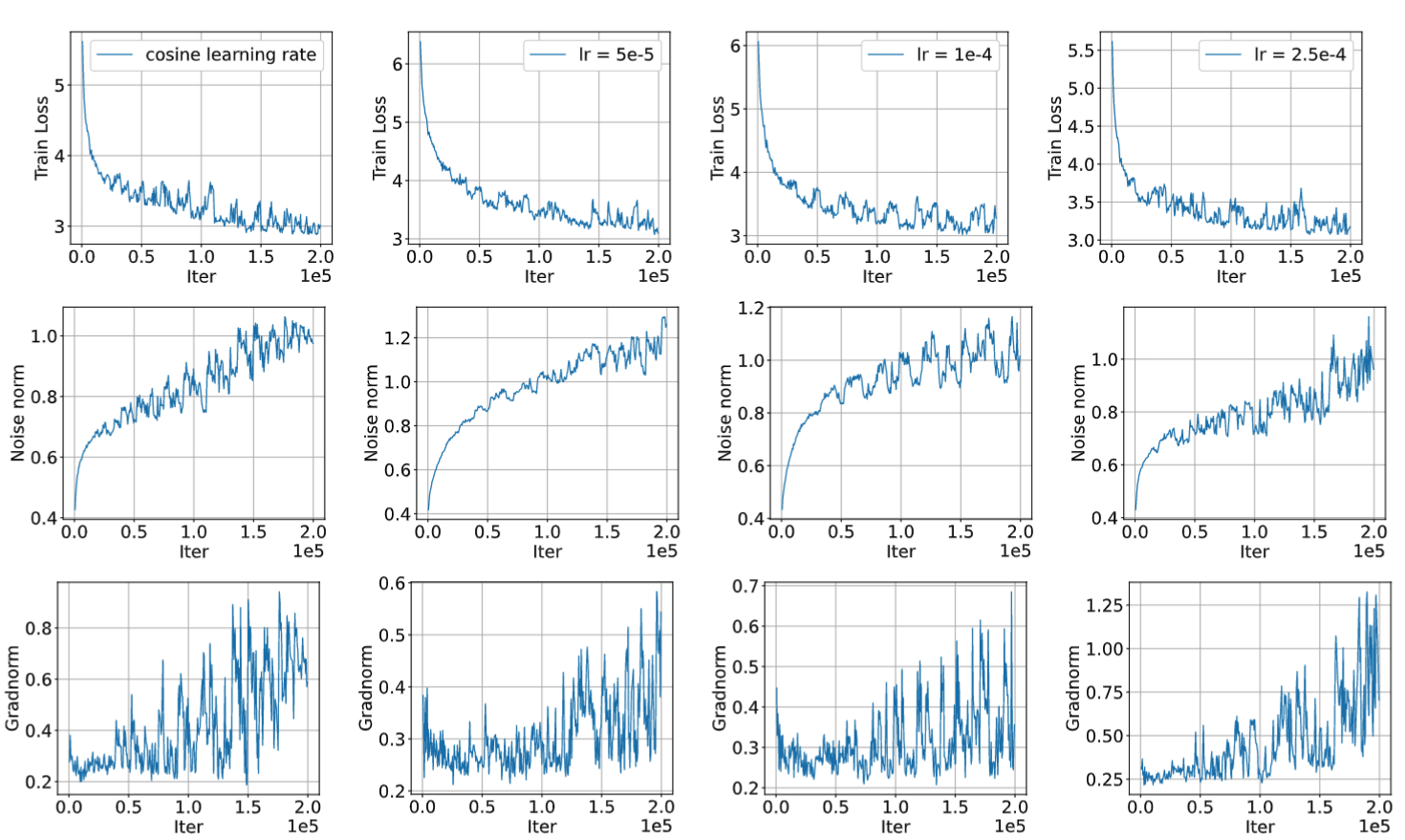
图2. 不同训练计划下的TransformerXL Wiki103 实验statistics
基于上述实验,该研究借助动力系统的invariant measure理念提出了一种新的收敛定义,即参数的时间平均收敛。该研究为这种收敛提供了神经网络优化的理论分析。此外,该研究还发现,实际中损失函数的平滑收敛,是由于估计器在时间维度做了平滑。
论文作者:交叉信息院助理教授张景昭。
论文链接:https://arxiv.org/pdf/2110.06256.pdf
供稿:交叉信息研究院
编辑:李华山
审核:吕婷











