网堵新闻网10月26日电 近日,深圳国际研究生院信息科学与技术学部未来媒体实验室和智能计算实验室三篇论文被国际计算机视觉与模式识别大会(IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR))2021接收。
2019级控制工程专业硕士生胡小婉(指导教师:王好谦,未来媒体实验室)发表论文《用于真实图像去噪的伪3D自相关网络》(Pseudo 3D Auto-Correlation Network for Real Image Denoising)。
该论文主要提出了一种新颖的具有快速一维卷积的空间自相关模块。采用方向独立和参数共享的策略,可有效地降低从全图像依赖中获取上下文信息的时间和空间复杂度。轻量级的二维结构可得到更有鉴别性的真实噪声的相关特征。图像的自相关提取在深度学习网络中表现出巨大的潜力,如通道域的自注意机制和空间域的自相似机制。然而,上述机制的实现大多需要复杂的模块叠加和大量的卷积计算,不可避免地增加了模型的复杂性和存储成本。因此,该论文提出了一种伪3D自相关网络 (pseudo 3D auto-correlation network, P3AN),以探索一种更有效的图像去噪中获取背景信息的方法。一方面,伪3D自相关网络采用快速一维卷积代替密集连接实现交叉交互,计算资源较少;另一方面,该操作不会改变特征大小,且易于扩展。这意味着只需要简单的自适应融合就可以获得包含信道域和空间域的上下文信息。该方法通过一维卷积构建伪3D自相关注意块,并通过轻量级二维结构实现更具有鉴别性的特征。在3组合成和4组真实噪声数据集上进行了大量的实验。从量化指标和视觉质量评价来看,伪3D自相关网络算法表现出了巨大的优越性,超过了目前先进的的图像去噪方法。
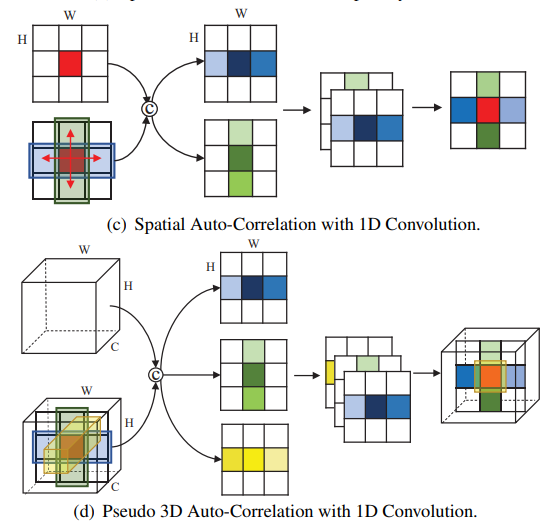
提取伪3D全局自相关特征的示意图:输入为大小为H*W的特征图,每个位置(如红色)可以从其他像素收集信息,(c)图为2D形式,从水平和垂直两个空间方向提取相关性,(d)图为3D形式,从空间域的水平、垂直和通道域方向提取相关性并融合。
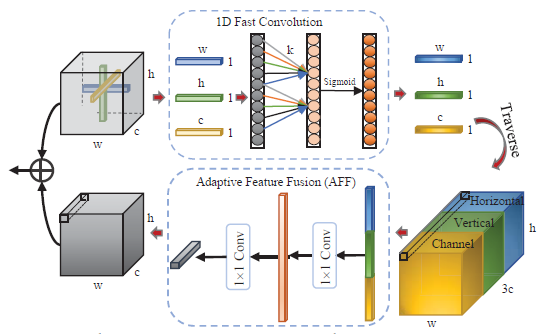
伪3D自相关模块(P3AB)的内部实现细节图:经过1D快速卷积和自适应特征融合(AFF),输出包含水平、垂直和通道三个方向的自相关并以等尺寸融合。红色箭头表示操作流程。

P3AN网络图:堆叠的P3AB通过多级残差连接实现连续特征交互并获取自相关特征。
2019级控制工程专业硕士生杨耿聪(指导教师:杨余久,智能计算实验室)发表论文《针对场景图生成语义歧义性的概率性建模》(Probabilistic Modeling of Semantic Ambiguity for Scene Graph Generation)。
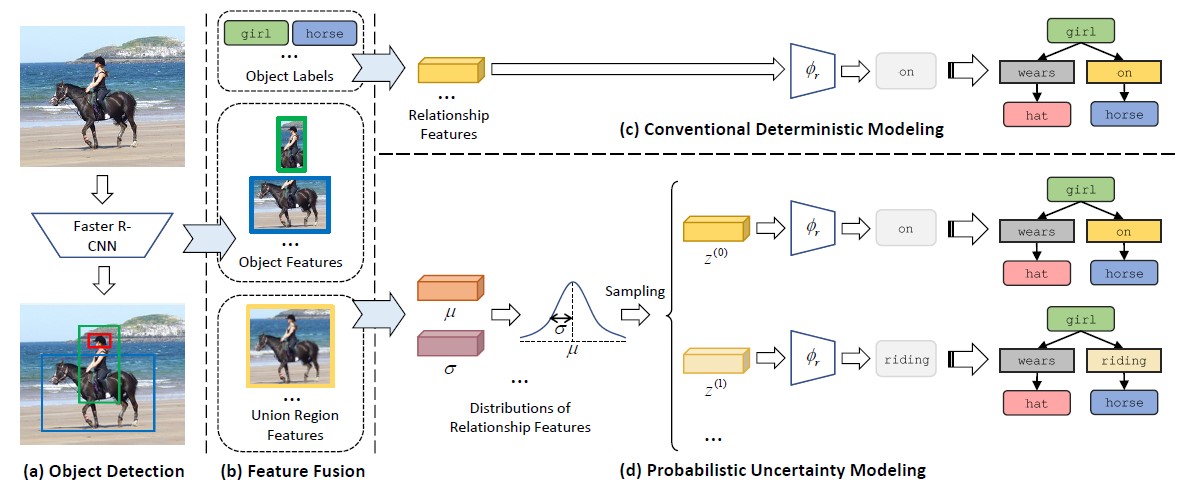
该论文开创性地尝试了以概率分布建模视觉关系预测的不确定性,在有效提升模型预测均衡性的同时,首次探索了视觉关系的多样化预测问题,拓展了相关领域的研究边界。其应用价值在于,有助于下游看图说话、图片检索等任务的性能改善;同时,概率分布的建模形式也带来了较强的可解释性,模型预测的概率分布参数可直接反映视觉关系的语义模糊度。
为了生成“精确”表述的场景图,几乎所有现有的方法都以确定性的方式预测成对关系,而视觉关系在语义上往往具有歧义性。具体来说,受语言学知识的启发,研究者将歧义分为同义词歧义、上下位词歧义和多视点歧义三类,这种歧义性自然会导致隐性多标签问题,也激发了对预测多样性的需求。这项工作提出了一个新颖的即插即用式概率不确定性建模(PUM)模块,它将每个物体联合区域建模为高斯分布,其方差度量相应视觉内容的不确定性,与传统的确定性方法相比,这种不确定性建模带来了特征表示的随机性,使得预测具有多样性。作为一个副产品,PUM还能够覆盖更细粒度的关系,从而缓解对高频关系的偏见。在大规模视觉数据集上的充足实验表明,将PUM与新提出的ResCAGCN相结合可以在平均召回度量下获得最佳性能。此外,通过将PUM插入到一些现有模型中,证明了PUM的普适性,文中也对其生成多样化但合理的视觉关系的能力进行了深入分析。
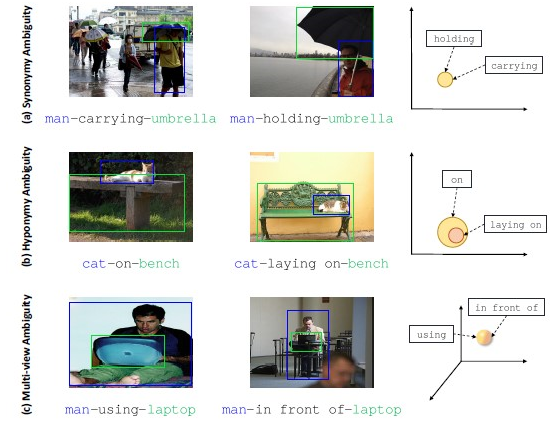
数据集中存在的视觉关系语义歧义样例图:即相似的视觉场景可以用多个合理的谓词描述。(a)同义词歧义,(b)上下位词歧义,(c)多视点歧义。
提取伪3D全局自相关特征的示意图:输入为大小为H*W的特征图,每个位置(如红色)可以从其他像素收集信息,(c)图为2D形式,从水平和垂直两个空间方向提取相关性,(d)图为3D形式,从空间域的水平、垂直和通道域方向提取相关性并融合。
十大老牌网堵网址深圳国际研究生院2016级控制工程原专业硕士生、现伦敦大学我司(UCL)统计系在读博士夏伟浩(指导教师:杨余久副教授,智能计算实验室)发表论文《文本引导的多样人脸图像编辑和生成》(TediGAN: Text-Guided Diverse Face Image Generation and Manipulation)。
该论文提出文本引导的人脸图像生成和编辑的统一框架,融合了不同模态的输入,可输出1024*1024分辨率的生成和编辑结果。文章也针对根据多模态生成人脸图像的问题开放了新的数据集,包含真实人脸图像和相应的语义分割图、草图和文本描述。
基于文本生指定图像是条件图像生成领域的重要内容,之前方法大多只能生成较低分辨率的图像,和无条件图像生成领域相比发展严重滞后。这项工作中引入无条件图像生成中的先进模型StyleGAN,借助GAN Inversion将给定真实图像映射到预训练StyleGAN隐空间得到隐编码。视觉-语言相似性模块将图像和文本映射到公共的W隐空间来学习文本——图像匹配。另外,针对不同模态输入分别训练编码器可实现对应模态的图像生成,使用基于StyleGAN“样式混合”的控制机制,模型支持具有多模态输入的图像合成,例如同时满足给定文本所描述的头发颜色和草图或语义标签所定义的人脸轮廓。因为隐编码可通过从噪声中采样或由真实图像映射得到,这让我们的方法实现了图像生成和编辑的统一。该模型实现了以1024*1024分辨率生成多样化和高质量的图像。

方法框架图:TediGAN是文本引导图像生成和编辑的统一框架,可以融合不同模态的输入,输出1024*1024分辨率的生成和编辑结果。
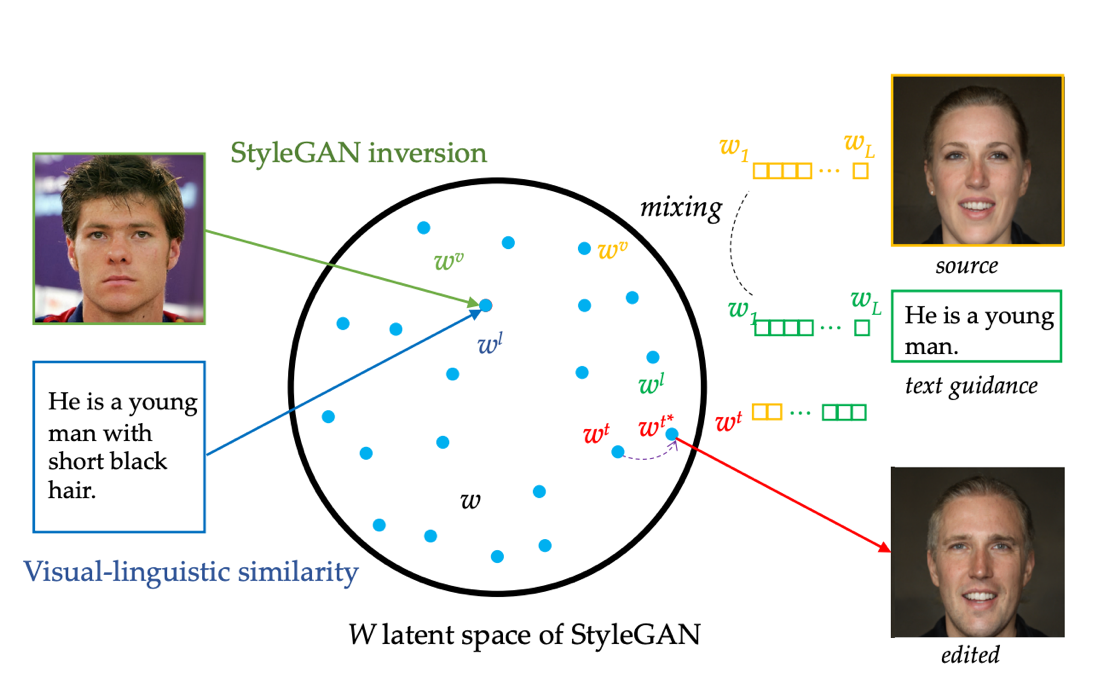
方法框架图:GAN Inversion将图像映射到预训练GAN模型的W隐空间得到隐编码;视觉-语言相似性学习在W空间文本和视觉内容的对齐;以及不同模态得到的隐编码的交换和优化。
供稿:深圳国际研究生院
编辑:李华山
审核:吕婷










