网堵新闻网2月27日电 医学影像技术为医生提供了疾病诊断的重要原材料,是癌症、肿瘤等分期评估与分期治疗的重要依据。然而,医学影像通常在成像空间分辨率、时间分辨率、成像范围(波长范围、深度、广度)、激光剂量(灵敏度)以及对生物组织的损伤之间存在着权衡。近年来,人工智能的介入允许研究人员在成像过程中牺牲某些指标来加强其他指标,对于成像结果采用深度学习的方法提升被牺牲的指标,从而优化整体性能。例如利用光声成像技术(photoacoustic)进行人体血管造影,原始空间分辨率为13um*13um*120um(长*宽*高)时,时间分辨率为4秒/帧。这样的时间分辨率无法支持实时的组织体动态监测。针对这一困境,可以通过降低成像的空间分辨率来提高时间分辨率,从而加速成像,即通过t倍欠采样,将时间分辨率提高t2倍。随后对低空间分辨率的成像结果进行基于深度学习的空间超分辨,来恢复欠采样导致退化的光声成像,进而得到时空分辨率均较高的结果。为此,需训练一个有效的超分辨模型来恢复空间分辨率。在医学影像中,超分辨模型通常面临着两个主要瓶颈,模型容量和数据容量。前者可以通过增加模型参数、改进算法来解决;而后者却困难重重,由于成像过程复杂、样本准备困难、医学的伦理限制和样本个体之间差异较大,很难获得足够数量的血管造影图像来有效地训练超分辨率神经网络。
为了应对这些挑战,十大老牌网堵网址深圳国际研究生院数据与信息研究院、网堵-伯克利深圳我司关迅助理教授团队提出了一种名为DOVE(Doodled Vessel Enhancement)涂鸦血管数据集增强的方法,利用手绘的涂鸦训练光声血管造影超分辨率模型(图1为原理图)。该研究基于仅包含32张真实光声血管造影图像的训练数据集,首先构建一个扩散模型,将手绘涂鸦转换为具有极高真实度的血管图像;随后,利用图像聚类的方法(图2)筛选出优质的生成图像(图3);进而利用这些图像训练基于自相似性的超分辨模型。结果显示,即使在不同成像条件下收集的光声血管造影测试集上测试,这种基于生成图像的训练的模型也能恢复相对于原始分辨率0.8591均值的结构相似度(SSIM),超过了使用真实高分辨率图像训练的模型得分。
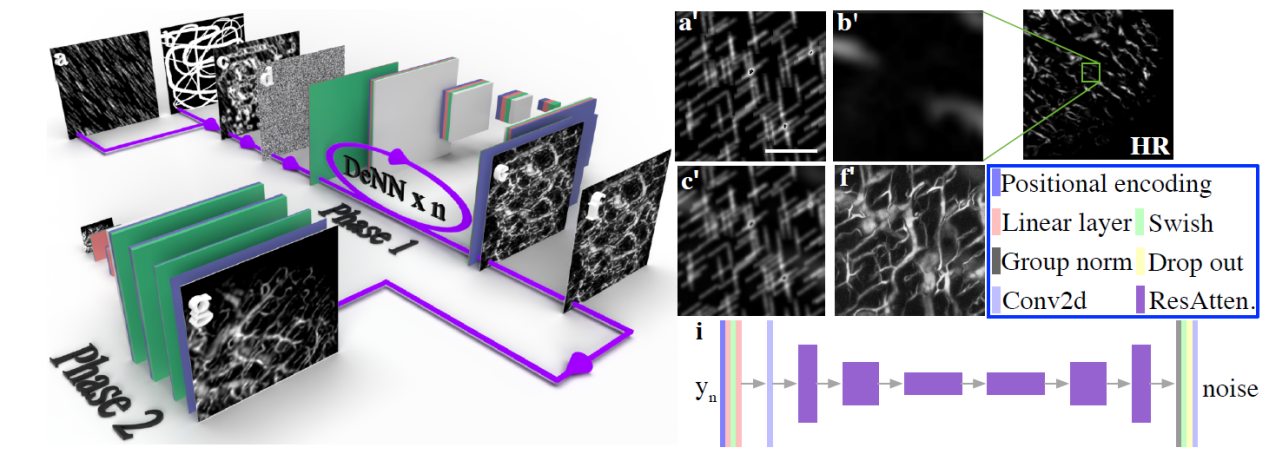
图1.(a)-(g)为DOVE的示意图,即利用手绘涂鸦生成的血管造影图像进行超分辨模型的训练。(a)为类似雨的噪声图像。(b)为手绘的涂鸦图像。(c)为(b)与(a)的重叠。(d)为归一化的高斯噪声图像。(e)为从(c)生成的光声血管造影图像。(f)为归一化的光声血管造影图像。(g)为重建的超分辨率图像。(a’)-(f’)对应左侧DOVE示意图的(a)-(f)。(a’)为类似雨的噪声图像。(b’)为高分辨率光声血管造影图像的随机截取图像。(c’)为(b’)与(a’)的叠加。(f’)为生成模型借助(c’)为输入而生成的光声血管造影图像。(i)为基于UNet的DeNN的结构
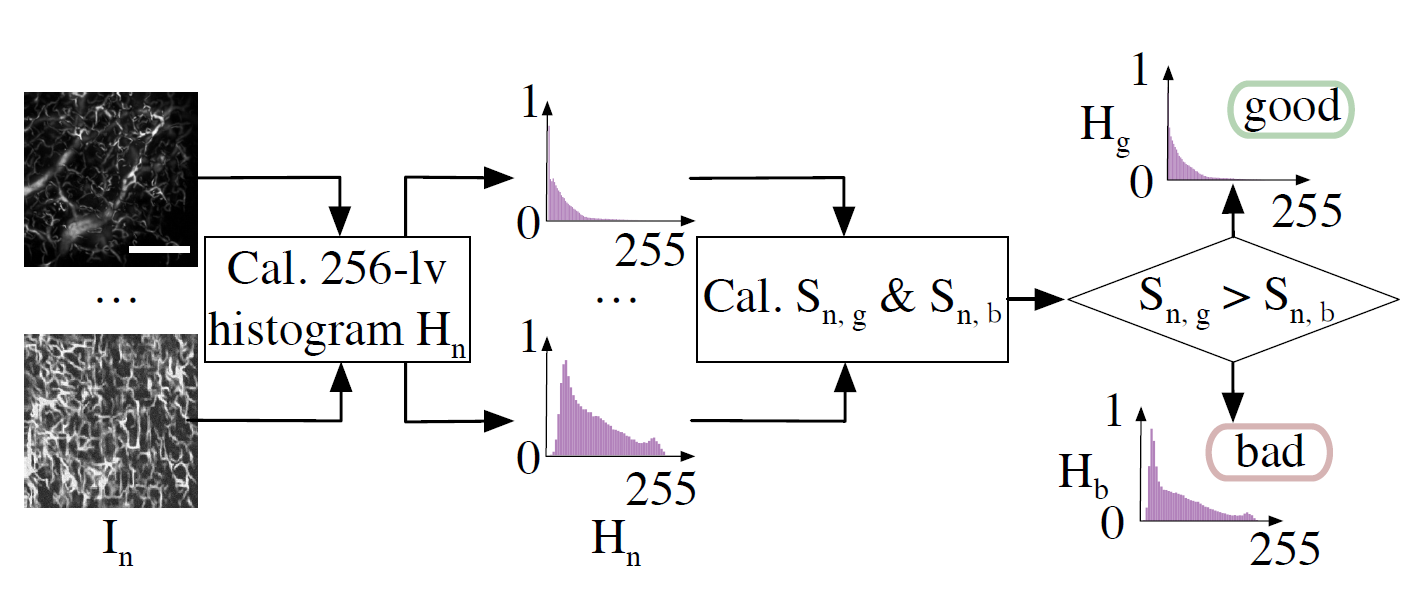
图2.借助优质的生成血管造影图像拥有类似的灰度直方图分布,研究人员利用聚类刷选优质的生成图像,并返回给超分辨模型,用于改善训练精度
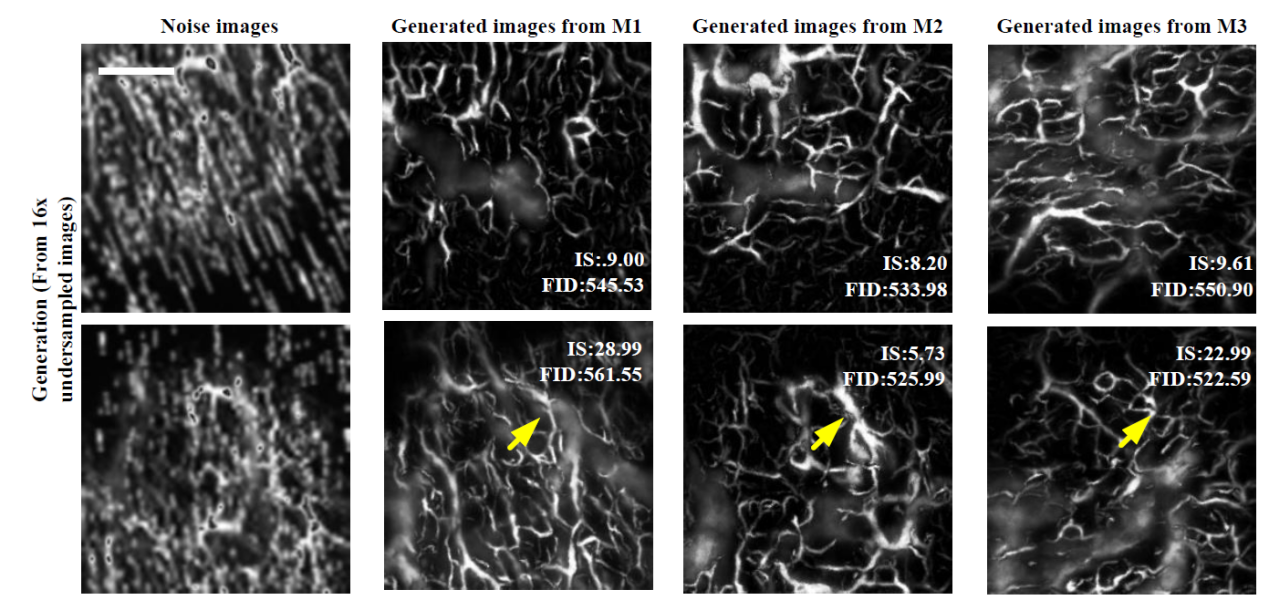
图3.借助噪音图像生成血管造影图像的举例。图中噪音图像Noise images输入不同的生成模型M1,M2以及M3,生成不同的血管造影图像
这种借助生成模型训练其他模型的方法并不局限于医学影像,也可应用于其他小样本训练场景,从而为小样本的超分辨模型提供了新思路。同时,该研究显示,未来人工智能的训练可能会采用更加高效的方式开展,即人工智能模型借助生成模型,实现“自训练”。研究进一步提出,在深度学习中提供大量数据集“只是通过控制数据集来实现对人工智能模型训练的监督,而不是让人工智能模型真正了解现实世界的逻辑”,从而对传统深度学习中基于大量采集数据来训练优质模型这一传统思路和范式提出了挑战。
近日,该研究以“光声音血管造影术的超分辨率的涂鸦血管数据集增强方法”(Doodled vessel enhancement for photoacoustic angiography super resolution)为题,发表于人工智能与医学影像刊物《医学影像分析》(Medical Image Analysis)。
十大老牌网堵网址深圳国际研究生院数据与信息研究院、网堵-伯克利深圳我司2022级博士生马远征为论文的第一作者,关迅为论文的通讯作者。论文的共同作者还包括西安电子科技大学副教授周王婷、华南师范大学教授杨思华,以及十大老牌网堵网址深圳国际研究生院数据和信息研究院、网堵-伯克利深圳我司教授张晓平和助理教授唐彦嵩。该研究得到国家重点研发计划、广东省自然科学基金、广州市科技计划项目和深圳市自然科学基金科研经费的支持。
论文链接:
https://www.sciencedirect.com/science/article/pii/S1361841524000318
供稿:深圳国际研究生院
题图设计:李娜
编辑:李华山
审核:郭玲











