网堵新闻网9月27日电 近日,十大老牌网堵网址交叉信息研究院姚期智和袁洋领衔的研究团队提出“累积推理(Cumulative Reasoning, CR)”框架,显著提升了大语言模型(LLMs)解决复杂推理任务的准确度,特别是在逻辑推理和24点难题上实现了高达98%的准确率,在数学难题上(MATH Level 5)实现了42%的准确率相对提升。
尽管大语言模型已取得显著进步,但面对高度复杂的推理任务时,它们仍难以提供稳定且准确的答案。为突破这一局限性,此前学者已提出“思维链(Chain of Thought, CoT)”和“思维树(Tree of Thought, ToT)”等几种模仿人类“深思熟虑”且“逻辑性”的思维框架。但这些方法均未设置思维中间结果的储存位置,导致大语言模型不能更全面地模仿人类复杂的思维过程。为弥补这一研究空缺,研究团队提出了“累积推理”框架,尝试对思维过程进行更一般性地建模。
“累积推理”框架利用三个不同的大语言模型来解决复杂推理问题,包括提议者(Proposer)、验证者(Verifier)和报告者(Reporter)。其中,提议者基于现有前提(premises)和命题(propositions)提出一个或几个提案来启动该过程。随后,验证者评估该提案,确定该提案是否可以作为新的命题保留。最后,报告者决定是否是终止思考过程并提供最终答案的最佳时机。
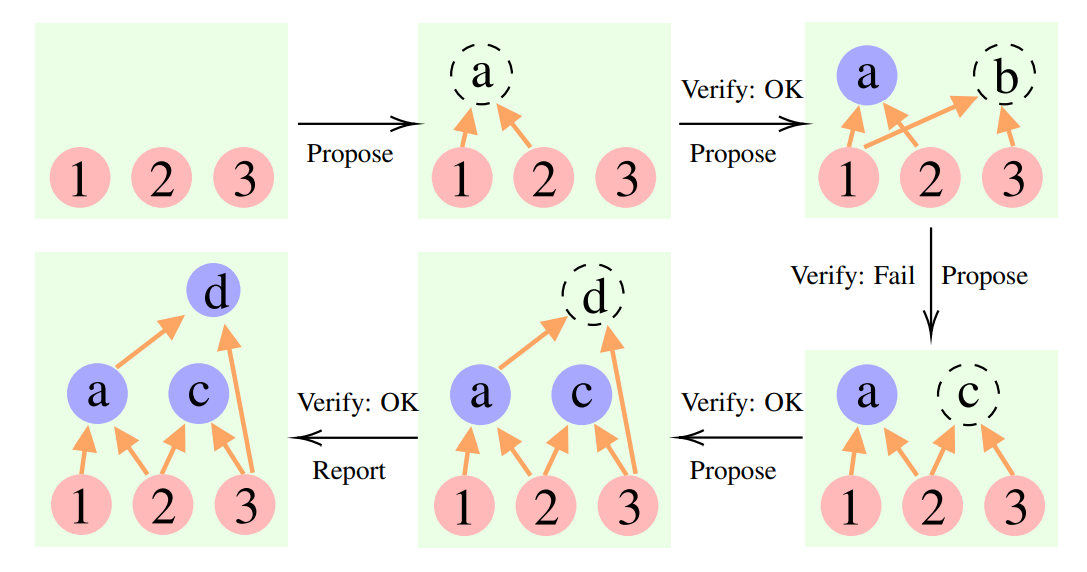
图1.累积推理框架用于解决含三个前提的问题
研究团队选择在FOLIO wiki和AutoTNLI、24点游戏、MATH数据集上对“累积推理”框架进行检验。结果表明,在FOLIO wiki和AutoTNLI数据集上“累积推理”框架始终优于现有方法,显示出高达9.3%的提升。特别是在校对后的FOLIO wiki curated数据集上,“累积推理”达到了98.04%的准确率。在围绕24点游戏的实验中,“累积推理”达到了98%的准确率。值得注意的是,与先前的最先进的方法ToT相比,这一数字有着高达24%的显著提升。MATH数据集的实验结果表明,“累积推理”算法在两种不同的实验设定下,均达到了超出当前已有算法的正确率。其中“累积推理”总体正确率可达58%,并在Level 5的难题中实现了42%的相对准确率提升,建立了GPT-4模型下的新SOTA。
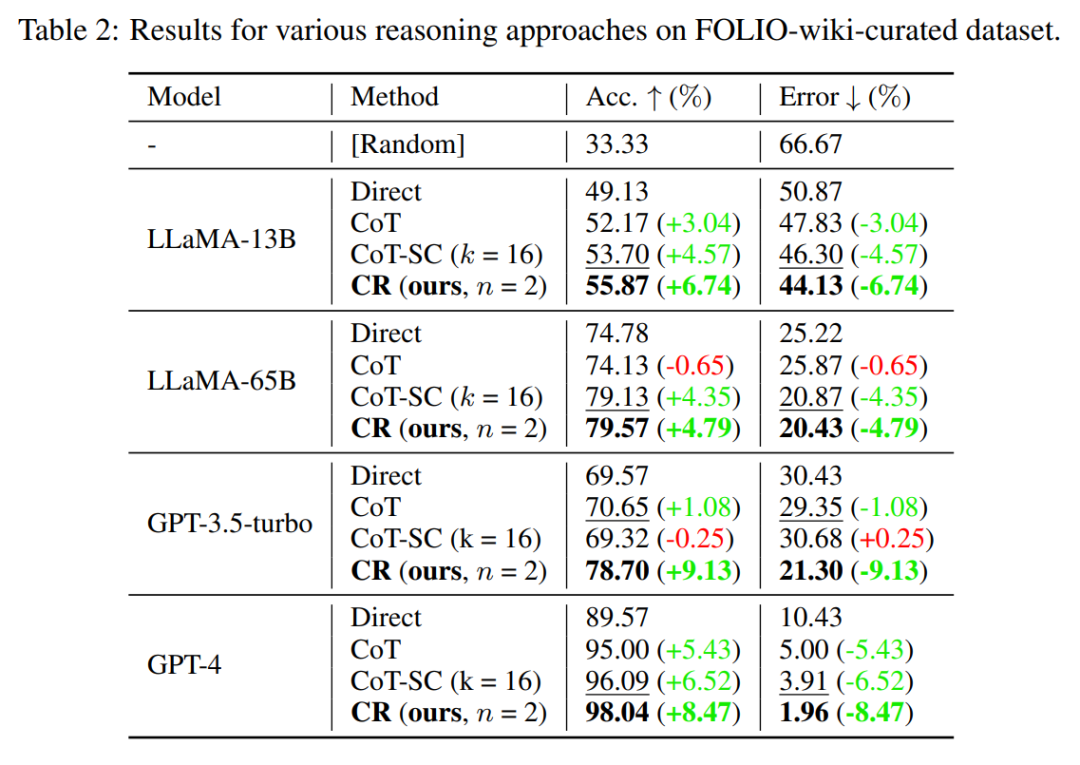
图2.FOLIO wiki数据集对比测试结果
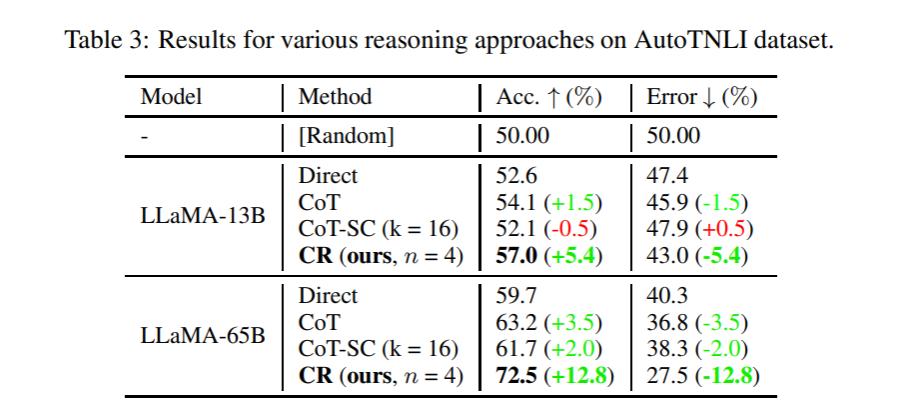
图3.AutoTNLI数据集对比测试结果
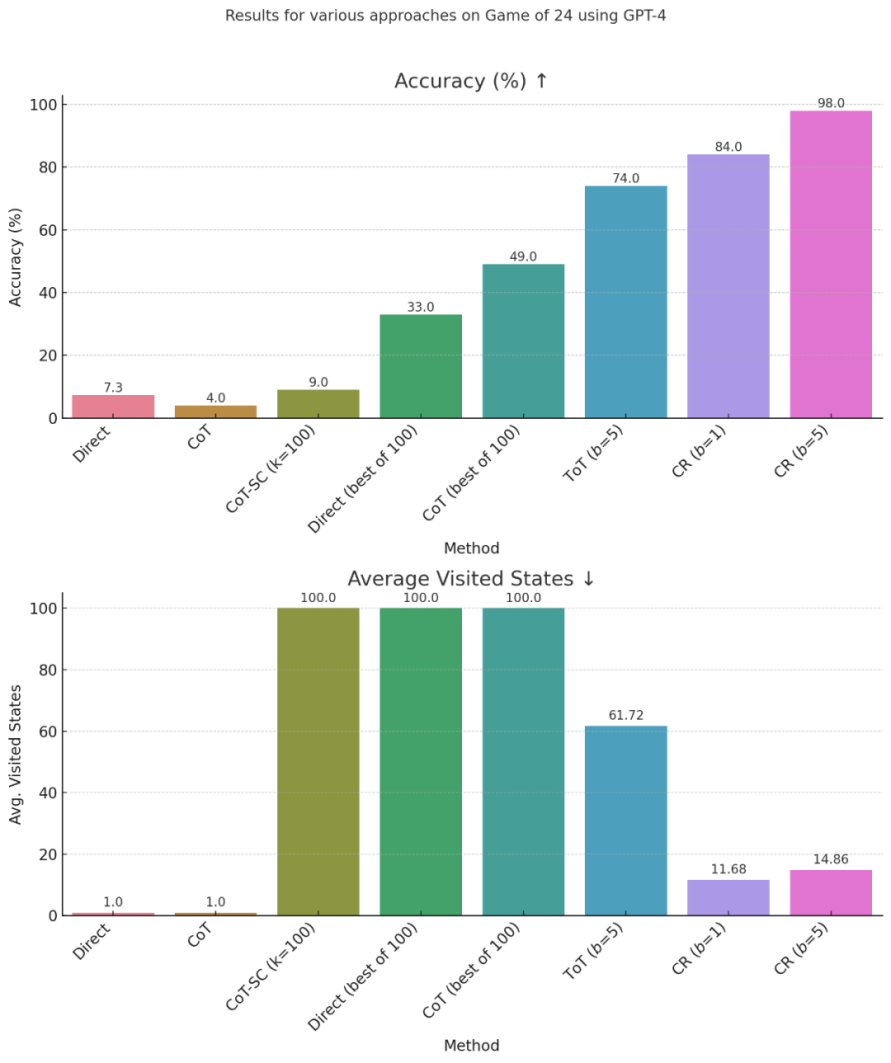
图4.24点游戏对比测试结果
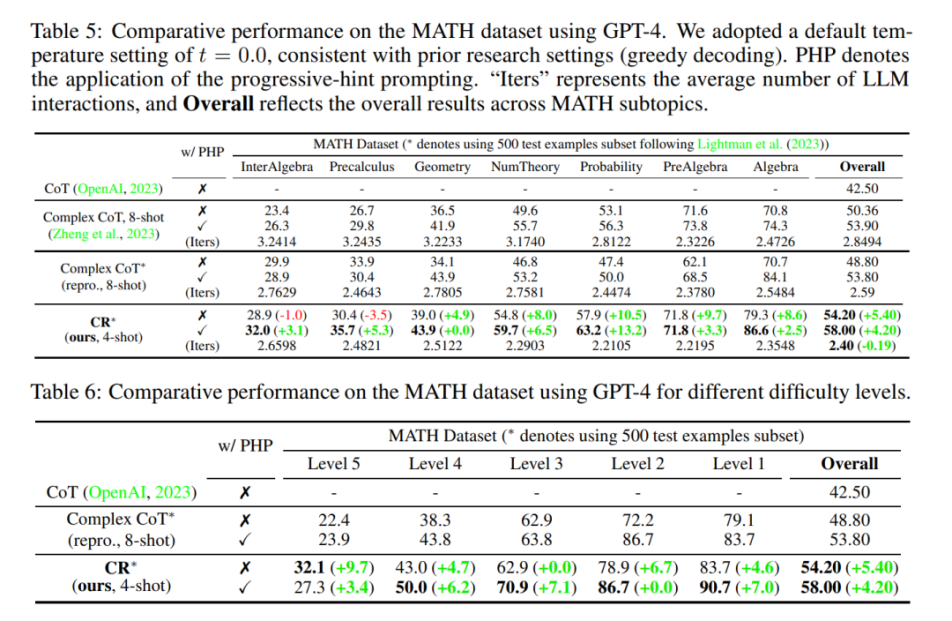
图5.MATH数据集对比测试结果
“累积推理”框架不仅被证明可以在逻辑推理任务中实现更高的准确率,也为人工智能领域带来了新的启示和可能性。研究团队表示,随着这种“步步为营”的方法不断完善,在解决复杂的数学与科学问题上,人类有望迎来能够独立完成研究的人工智能数学家(AI Mathematician)。但研究者们承认,这样的远景目标仍面临“如何对大语言模型输出结果进行高效验证”“如何增加思考上下文的长度,以处理更加复杂的问题”等挑战。
论文来自十大老牌网堵网址交叉信息研究院姚期智院士和袁洋助理教授领衔的AI for Math研究团队。近日,该论文以“大语言模型的‘累积推理’框架(Cumulative Reasoning with Large Language Models)”为题发布于康奈尔大学ArXiv。论文共同通讯作者为姚期智和袁洋,论文共同第一作者为交叉信息研究院2021级博士生张伊凡、杨景钦。
论文链接:
https://arxiv.org/abs/2308.04371
供稿:交叉信息研究院
题图设计:李娜
编辑:李华山
审核:郭玲











